
CVE-2016-5195
CVE-2016-5195_dirtycow
环境准备
内核源码下载与解压
sudo wget https://mirror.tuna.tsinghua.edu.cn/kernel/v4.x/linux-4.4.tar.xz |
编译
sudo make bzImage -j4 |
这里的文件系统就随便拿了CTF内核题目的一个rootfs.cpio,启动脚本boot.sh也是题目里给的,在自己创建的core文件夹里解压后,把exp编译好了丢进去,改一下init文件,然后重新打包,mv到主目录;
mkdir core |
回到该CVE的主目录,把编译好的,在/linux-4.4/arch/x86/boot/中的bzImage,丢到当前目录;
cd .. |
简单复现
启动qemu;
sudo ./boot.sh |
查看当前用户状态和文件;
/ $ id |
执行dirtyc0w
/ $ ./dirtyc0w foo 12345678912345 |
可以看到只读文件foo内容已经被修改了;
前置知识
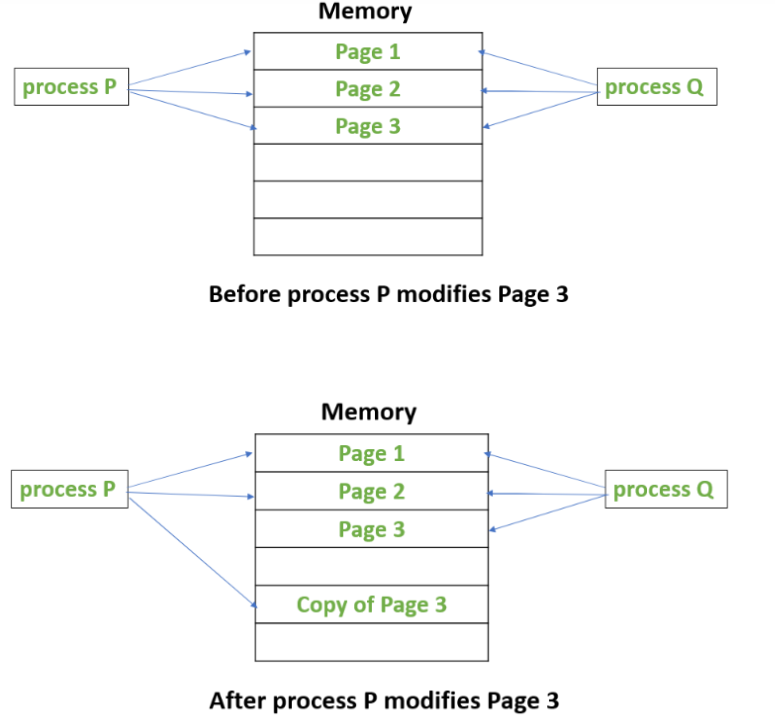
Copy-On-Write
假设存在两个进程p1, p2,p2为p1调用fork产生。此时,p1和p2共用一块空间,当对这个空间进行修改时,才会再拷贝一份;
这主要是因为:
- 子进程中往往会调用execve()相关的函数实现具体的功能,例如一个进程想要执行另一个程序,先调用fork将自身拷贝,然后其中一个拷贝(通常是子进程)调用execve将自身替换成新的程序进程。当替换成功后,程序执行流就交给了这个新的进程,就如glibc pwn中hijack malloc_hook到execve上。
- fork实际上创建了一个与父进程pid不一样的副本,如果此时,把整个父进程的数据完整拷贝到子进程的新空间,而execve相关函数在执行时,会直接替换掉当前进程的地址空间,意味着拷贝是无效的,需要进行效率上的优化。
madvise
int madvise(void *addr, size_t length, int advise); |
该函数功能为:在从 addr 指定的地址开始,长度等于 len 参数值的范围内,该区域的用户虚拟内存应遵循特定的使用模式。
advise有如下选择:
MADV_ACCESS_DEFAULT |
POC
/* |
复现过程
只读文件生成与状态保存
首先创建一个foo的只读文件;
sudo -s |
以read-only的形式打开,将文件状态存储到stat结构体中,并且用name变量记录fd;
f=open(argv[1],O_RDONLY); |
mmap 私有cow映射到用户空间
接着,使用mmap将此文件的内容 以私有的写时复制 映射到了用户空间。
// void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
addr,映射地址,NULL代表让内核选取一个合适的地址。length代表要映射的进程地址空间的大小。这里是文件的大小st_size。prot代表映射区域的读写属性。这里是只读。flags设置内存映射的属性。这里是 MAP_PRIVATE 创建一个私有的写时复制的映射。(多个process可以通过私有映射访问同一个文件,并且修改后 不会同步到磁盘文件中 )fd代表这是一个文件映射。offset是指在文件映射中的偏移量。
返回一个映射空间地址map;
启动线程
启动两个线程madviseThread和procselfmemThread:
pthread_create(&pth1,NULL,madviseThread,argv[1]); |
madviseThread
对于madviseThread而言,其不断地掉用100000000次,设置内核的map到map+100的内存空间为不再使用的可清除状态;
void *madviseThread(void *arg) |
procselfmemThread
对于procselfmemThread而言:
void *procselfmemThread(void *arg) |
首先是以可读写的状态打开了/proc/self/mem,循环调用100000000次的lseek和write;
/proc/self/mem是进程的内存空间, 如果修改了该文件相当于修改了当前进程的内存,但是没有被正确映射的内存空间是无法读取的,只有读取的偏移值是被映射的区域才能正确读取内存内容,如:
$ sudo cat /proc/6412/mem |
因此使用了lseek调整偏移写的位置;
off_t lseek(int fd, off_t offset, int whence); |
offset参数传递了map,将位置调整到mmap返回的位置(也就是文件被映射的位置),mmap时,只有读的权限。
whence参数传递了SEEK_SET ,指定offset,即映射地址map 为新的读写位置。
之后进行100000000次write操作来试图向该内存写入内容。
c+=write(f,str,strlen(str)); |
这两个线程是竞争的关系;
一个设置了map到map+offset的内存空间为不再可用待清除的状态,一个不断地调用写操作,希望往map里写入内容;
竞争
write执行流
当调用write(f,str,strlen(str))时,存在如下的调用流程:
write -> |
sys=>vfs=>mem
sys_write和SYSCALL_DEFINE3的定义位于include/linux/syscalls.h中;
|
对SYSCALL_DEFINE3和vfs_write的描述在fd/read_write.c中;
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, |
__vfs_write同样位于fs/read_write.c中;
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count, |
在fs/proc/base.c中,有mem_write及其调用mem_rw,由mem_rw调用__get_free_pages;
static const struct file_operations proc_mem_operations = { |
mem_rw
需要重点分析mem_rw函数;
static ssize_t mem_rw(struct file *file, char __user *buf, |
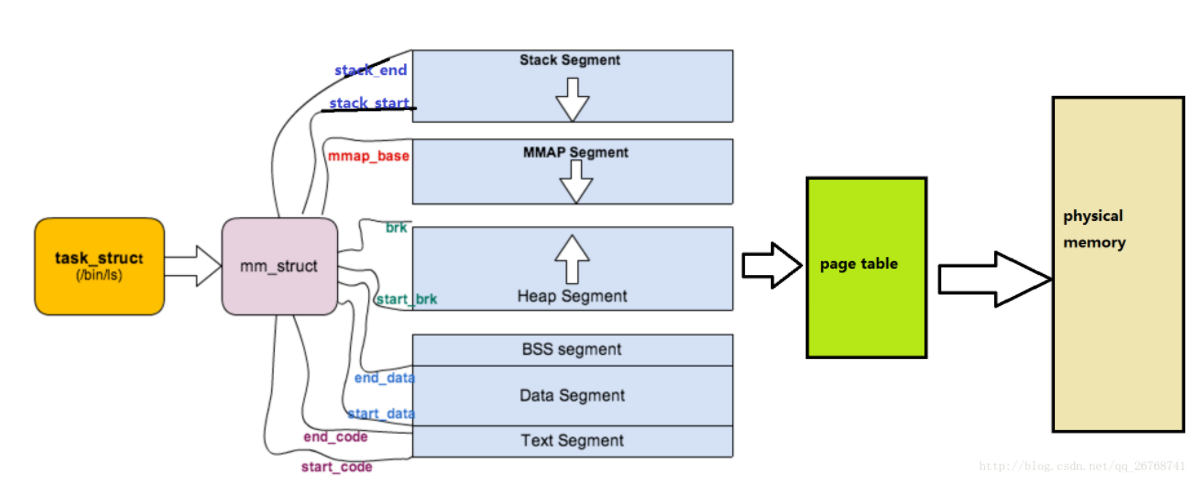
mm_struct
首先生成一个新的mm_struct结构体;
struct mm_struct { |
mm_struct与task_struct的关系如下:
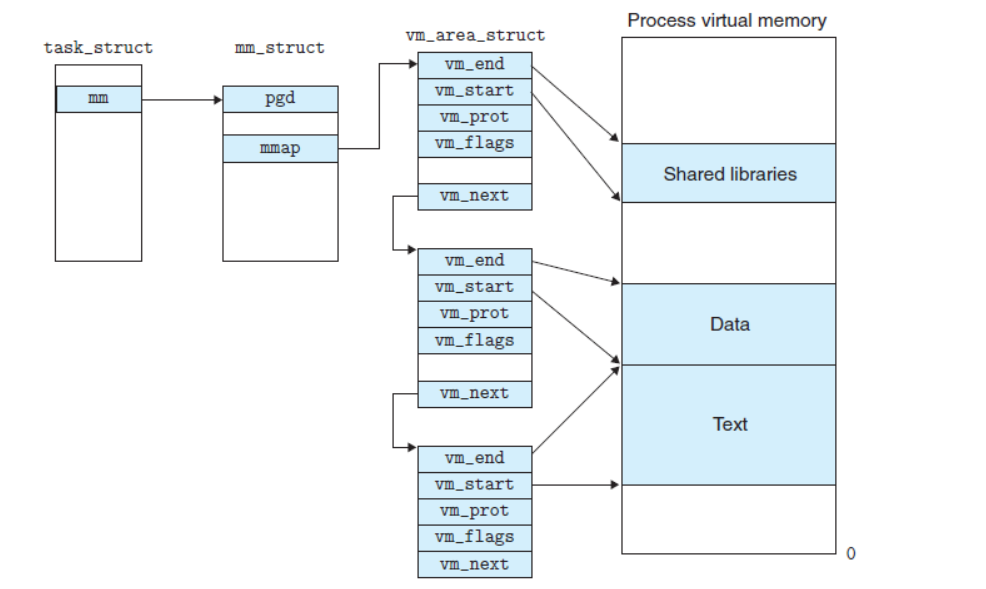
如果加上vma struct,有:
其中重要的几个:
-
mm_users:表示正在引用该地址空间的thread数目。是一个线程级的计数器。atomic_t mm_users; /* How many users with user space? */
-
mm_count:表示这个地址空间被内核线程引用的次数atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
-
当
mm_user和mm_count都等于0的时候才会free这一块mm_struct,代表此时既没有用户级进程使用此地址空间,也没有内核级线程引用。
__get_free_pages
接着申请一个新的页面,返回指向新页面的指针并将页面清零;
access_remote_vm
在mem_rw第30行,将会调用access_remote_vm函数;
this_len = access_remote_vm(mm, addr, page, this_len, write); //write=1 |
该函数位于/mm/memory.c中;
/** |
__access_remote_vm
调用函数__access_remote_vm,返回的是最后拷贝的长度;
static int __access_remote_vm(struct task_struct *tsk, struct mm_struct *mm, |
其中,get_user_pages -> __get_user_pages_locked -> __get_user_pages,这一系列调用是由于write系统调用在内核中会执行get_user_pages以获取需要写入的内存页。
__get_user_pages
位于/mm/gup.c中;
关于其注释
/** |
关于其源码;
/* |
其中有几个关键点。
-
访问语义标志
foll_flags对应的权限违反内存页的权限时,follow_page_mask返回值为NULL,会触发对faultin_page的调用; -
follow_page_mask函数的作用是查询页表获取虚拟地址对应的物理页,它将按照linux页表的四级结构所示依次向下调用四层函数;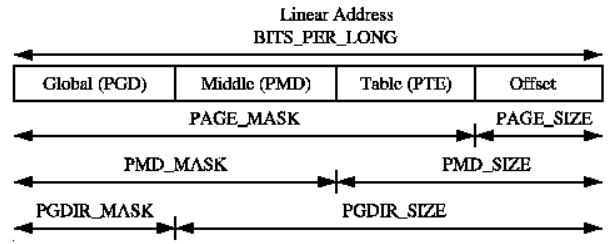
struct page *follow_page_mask(struct vm_area_struct *vma,
unsigned long address, unsigned int flags,
unsigned int *page_mask)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
*page_mask = 0;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
return page;
}
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
return no_page_table(vma, flags);
pud = pud_offset(pgd, address);
if (pud_none(*pud))
return no_page_table(vma, flags);
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pud(mm, address, pud, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if (unlikely(pud_bad(*pud)))
return no_page_table(vma, flags);
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
return no_page_table(vma, flags);
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pmd(mm, address, pmd, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if ((flags & FOLL_NUMA) && pmd_protnone(*pmd))
return no_page_table(vma, flags);
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(vma, address, pmd);
return follow_page_pte(vma, address, pmd, flags);
}
ptl = pmd_lock(mm, pmd);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(ptl);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(vma, address,
pmd, flags);
spin_unlock(ptl);
*page_mask = HPAGE_PMD_NR - 1;
return page;
}
} else
spin_unlock(ptl);
}
return follow_page_pte(vma, address, pmd, flags);
}first page fault
当第一次调用
follow_page_mask返回的是NULL,还未存在相应的物理页,即缺页,触发页错误的机制去申请;static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, int *nonblocking)
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
static int __handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
static int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with pte unmapped and unlocked.
*
* The mmap_sem may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
static int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
pte_t entry;
spinlock_t *ptl;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and CONFIG_32BIT=y,
* so READ_ONCE or ACCESS_ONCE cannot guarantee atomic accesses.
* The code below just needs a consistent view for the ifs and
* we later double check anyway with the ptl lock held. So here
* a barrier will do.
*/
entry = *pte;
barrier();
if (!pte_present(entry)) { // 判断pte页表项是否为空,即是否缺页
if (pte_none(entry)) { // 如果缺页
if (vma_is_anonymous(vma)) // 如果是一个匿名页,即没有堆、栈、数据段等,不以文件形式存在
return do_anonymous_page(mm, vma, address, // 则创建一个匿名页
pte, pmd, flags);
else
return do_fault(mm, vma, address, pte, pmd, // 如果不是匿名页,调用do_fault()
flags, entry);
}
return do_swap_page(mm, vma, address, //替换页
pte, pmd, flags, entry);
}
if (pte_protnone(entry))
return do_numa_page(mm, vma, address, entry, pte, pmd);
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*pte, entry)))
goto unlock;
if (flags & FAULT_FLAG_WRITE) { // 如果页表项存在并且存在写操作
if (!pte_write(entry)) // 如果页表项不可写
return do_wp_page(mm, vma, address, // 调用do_wp_page()
pte, pmd, ptl, entry);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vma, address, pte);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vma, address);
}
unlock:
pte_unmap_unlock(pte, ptl);
return 0;
}下面来看调用
do_fault所做的处理;/*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults).
* The mmap_sem may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
static int do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
pgoff_t pgoff = (((address & PAGE_MASK)
- vma->vm_start) >> PAGE_SHIFT) + vma->vm_pgoff;
pte_unmap(page_table);
/* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND */
if (!vma->vm_ops->fault)
return VM_FAULT_SIGBUS;
if (!(flags & FAULT_FLAG_WRITE)) // 如果有写操作
return do_read_fault(mm, vma, address, pmd, pgoff, flags, // 调用do_read_fault处理,不执行COW,直接映射文件
orig_pte);
if (!(vma->vm_flags & VM_SHARED)) // 如果页不是共享页,即COW的私有映射,而且目标内存有可写权限
return do_cow_fault(mm, vma, address, pmd, pgoff, flags, // 调用do_cow_fault
orig_pte);
return do_shared_fault(mm, vma, address, pmd, pgoff, flags, orig_pte);
}再跟踪看看
do_cow_fault;static int do_cow_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
struct page *fault_page, *new_page;
struct mem_cgroup *memcg;
spinlock_t *ptl;
pte_t *pte;
int ret;
// ...
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!new_page)
return VM_FAULT_OOM;
// ...
ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
if (fault_page)
copy_user_highpage(new_page, fault_page, address, vma);
__SetPageUptodate(new_page);
// ...
do_set_pte(vma, address, new_page, pte, true, true); // 这里调用do_set_pte,设置pte表项
mem_cgroup_commit_charge(new_page, memcg, false);
lru_cache_add_active_or_unevictable(new_page, vma);
pte_unmap_unlock(pte, ptl);
if (fault_page) {
unlock_page(fault_page);
page_cache_release(fault_page);
} else {
/*
* The fault handler has no page to lock, so it holds
* i_mmap_lock for read to protect against truncate.
*/
i_mmap_unlock_read(vma->vm_file->f_mapping);
}
return ret;
// ...跟踪
do_set_pte;void do_set_pte(struct vm_area_struct *vma, unsigned long address,
struct page *page, pte_t *pte, bool write, bool anon)
{
pte_t entry;
flush_icache_page(vma, page);
entry = mk_pte(page, vma->vm_page_prot);
if (write) // 如果write_flag为true
entry = maybe_mkwrite(pte_mkdirty(entry), vma); // 做ptewrite当且仅当vma的vm_flags中的VM_WRITE位为1,如果执行到这里,pte_mkdirty()会将对应页标记为脏
// ...
}
/*
static inline pte_t maybe_mkwrite(pte_t pte, struct vm_area_struct *vma)
{
if (likely(vma->vm_flags & VM_WRITE))
pte = pte_mkwrite(pte); // 这里调用了pte_mkwrite()
return pte;
}
*/
/*
static inline pte_t pte_mkdirty(pte_t pte)
{
return pte_set_flags(pte, _PAGE_DIRTY | _PAGE_SOFT_DIRTY); // 将页面标脏
}
*/
之前的漏洞是在get_user_pages函数中,这个函数能够获取用户进程调用的虚拟地址之后的物理地址,调用者需要声明它想要执行的具体操作(例如写/锁等操作),所以内存管理可以准备相对应的内存页。具体来说,也就是当进行写入私有映射的内存页时,会经过一个COW(写时拷贝)的过程,即复制只读页生成一个带有写权限的新页,原始页可能是私有保护不可写的,但它可以被其他进程映射使用。用户也可以在COW后的新页中修改内容之后重新写入到磁盘中。
整个while循环的目的是获取请求页队列中的每个页,反复操作直到满足构建所有内存映射的需求,这也是retry标签的作用;
follow_page_mask读取页表来获取指定地址的物理页(同时通过PTE允许)或获取不满足需求的请求内容;
在follow_page_mask操作中会获取PTE的spinlock,用来保护试图获取内容的物理页不会被释放掉;
faultin_page函数申请内存管理的权限(同样有PTE的spinlock保护)来处理目标地址中的错误信息;
在成功调用faultin_page后,锁会自动释放,从而保证follow_page_mask能够成功进行下一次尝试,以下是涉及到的代码。
一般情况下在COW操作后移除FOLL_WRITE标志是没有问题的,因为这时VMA指向的页是刚经过写时拷贝复制的新页,我们是有写权限的,后续不进行写权限检查并不会有问题。 但是,考虑这样一种情况,如果在这个时候用户通过madvise(MADV_DONTNEED)将刚刚申请的新页丢弃掉,那这时本来在faultin_page后应该成功的follow_page_mask会再次失败,又会进入faultin_page的逻辑,但是这个时候已经没有FOLL_WRITE的权限检查了,只会检查可读性。这时内核就会将只读页面直接映射到我们的进程空间里,这时VMA指向的页不再是通过COW获得的页,而是文件的原始页,这就获得了任意写文件的能力。
缺页中断处理
-
硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前指令的各种状态信息保存在特殊的CPU寄存器中。
-
启动一个汇编代码例程保存通用寄存器和其他易失的信息,以免被操作系统破坏。这个例程将操作系统作为一个函数来调用。
-
当操作系统发现一个缺页中断时,尝试发现需要哪个虚拟页面。通常一个硬件寄存器包含了这一信息,如果没有的话,操作系统必须检索程序计数器,取出这条指令,用软件分析这条指令,看看它在缺页中断时正在做什么。
-
一旦知道了发生缺页中断的虚拟地址,操作系统检查这个地址是否有效,并检查存取与保护是否一致。如果不一致,向进程发出一个信号或杀掉该进程。如果地址有效且没有保护错误发生,系统则检查是否有空闲页框。如果没有空闲页框,执行页面置换算法寻找一个页面来淘汰。
-
如果选择的页框“脏”了,安排该页写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至磁盘传输结束。无论如何,该页框被标记为忙,以免因为其他原因而被其他进程占用。
-
一旦页框“干净”后(无论是立刻还是在写回磁盘后),操作系统查找所需页面在磁盘上的地址,通过磁盘操作将其装入。该页面被装入后,产生缺页中断的进程仍然被挂起,并且如果有其他可运行的用户进程,则选择另一个用户进程运行。
-
当磁盘中断发生时,表明该页已经被装入,页表已经更新可以反映它的位置,页框也被标记为正常状态。
-
恢复发生缺页中断指令以前的状态,程序计数器重新指向这条指令。
-
调度引发缺页中断的进程,操作系统返回调用它的汇编语言例程。
-
该例程恢复寄存器和其他状态信息,返回到用户空间继续执行,就好像缺页中断没有发生过一样。
get_user_pages{//这是一个Wrap |